I tested 5 API caching techniques – here’s what actually improved performance
Looking to scale your API? Learn the various API caching strategies and how they increase server throughput.
 Emmanuel IsenahMarch 20, 2025
Emmanuel IsenahMarch 20, 2025
To render a satisfactory user experience, applications need to produce near-instant responses. Even a small delay of a few hundred milliseconds can leave users frustrated and ultimately hurt customer retention rates. And let's face it, nobody wants that.
That's where API caching comes in. By caching data, we cut down on the need to recompute it every time we need to access it—thereby reducing latency. Among the various techniques to improve API efficiency, caching typically stands out as the first line of defense.
A presentation by Amazon's former software engineer Greg Linden really drove this point home for me, showing that every 100 milliseconds of latency costs the company 1% in sales. I can't agree more with this point. Just the other day, I was on an online store, and the slow loading time made me abandon my cart in frustration (talk about a missed sale 🙃).
Now, to be fair, there are dozens of resources talking about API caching out there. But I felt it was worth summarizing the topic myself in a simple guide, almost as if I were about to learn this for the first time.
In this article, we will dive into various API caching strategies and examples. We will explain how caching works, and spotlight common mistakes to avoid.
Before closing out, we will also examine a few real-world scenarios that demonstrate the effects of caching at scale.
What is caching and why is it important?
Caching is the process of temporarily storing frequently accessed data in faster storage for future quick retrieval. This could be done either in-memory or on disk.

In the context of REST APIs, caching involves storing the results of expensive computations or database queries so that subsequent requests for the same data can be fulfilled much more quickly.
So, why should we cache data?
Many might not realize that database queries aren’t always fast. For instance, I have a personal blog where users can upvote or downvote my posts.
The data is stored in a relational database hosted on Supabase, and each vote by a user is logged in a junction table.
When I need to retrieve the total likes on a post, the database engine has to join multiple tables, which takes about 150 milliseconds to process the query and respond. In contrast, retrieving the same information from my hosted Redis cache takes less than 50 milliseconds.
This just goes to show the difference between recalculating data versus simply fetching it from cache. The latter will always be faster.
For complex database queries that involve even more tables and JOIN clauses, the difference becomes even more pronounced, leading to significant delays in response time.
Types of cache
When discussing caching within the server context, there are generally two main types to know:
Private сache
This type of cache is specific to the process running an application and is often referred to as a local cache. It holds data relevant to that particular process, which means it’s not accessible by other instances. For example, if you have multiple servers running your application, each one maintains its own independent cache storing its copy of the data. This is analogous to client-side api caching, where data is stored locally in the user's browser.
Shared сache
In contrast, a shared cache is accessible to multiple clients and allows different application instances to view the same cached data.
This type of cache is typically hosted as a separate service and facilitates data sharing across instances.
In the next section, where I discuss caching strategies, I'll be speaking from the point of shared caches.
API caching strategies
Cache aside
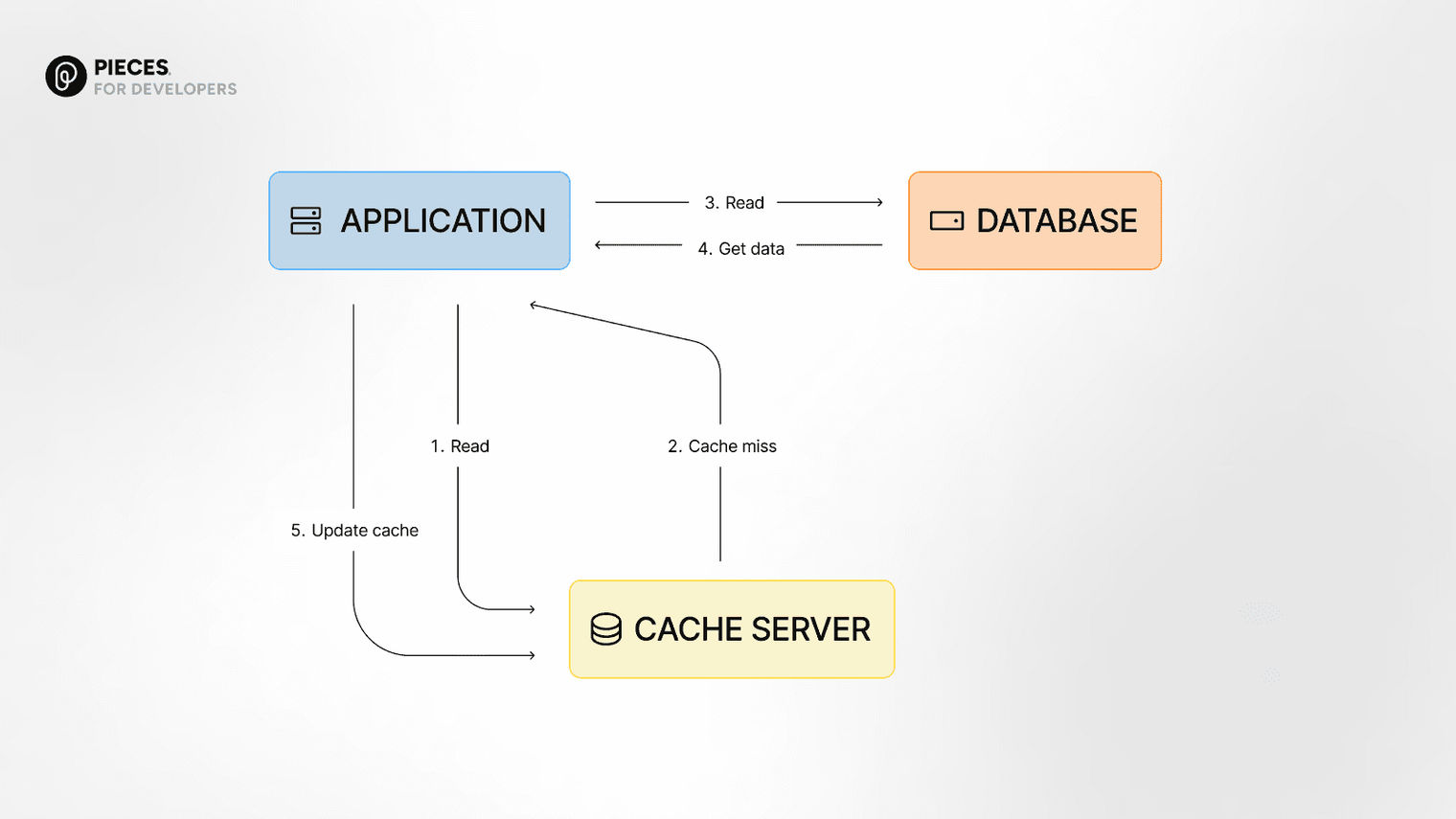
Think of this strategy as a lazy way to load data into cache. With this strategy, your application is responsible for managing the cache. To retrieve data, it first checks the cache to see if it exists.
If the data is there, great—it uses that instead. If not, it goes to the database, pulls the data, and saves it in the cache for next time.
async function getData(key: string): Promise<any> {
let data = await redis.get(key); // Read data from cache
if (!data) {
// Data is not cached, fetch from database (pseudo-code)
data = await fetchFromDatabase(key);
await redis.set(key, JSON.stringify(data)); // Cache the data
} else {
data = JSON.parse(data); // Parse cached data
}
return data;
}
When to use: This strategy is ideal for data that doesn’t change frequently. Just remember—having a solid plan for updating or clearing the cache is essential to avoid serving stale information.
Read through
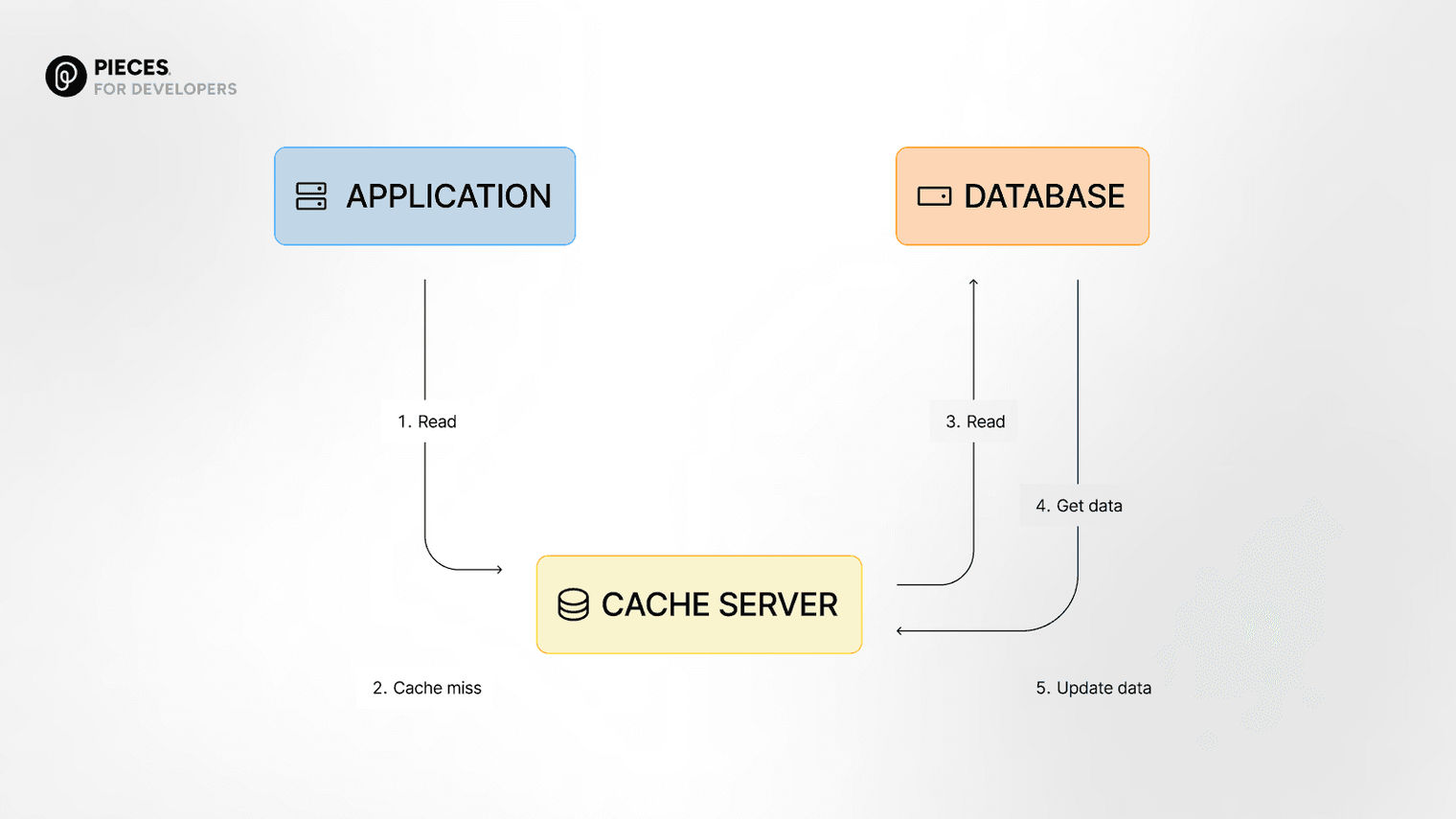
In read-through caching, the cache is responsible for keeping itself up to date automatically. This is different from cache-aside where the application handles this manually.
With this method, when your application asks for data, it first checks the cache. If it’s missing, the cache then automatically fetches it from the database, stores it, and hands it back to the application.
async function readThroughFn(key: string): Promise<any> {
// Read data from cache
// If cache miss, the cache server will automatically fetch from the database and update itself
let data = await cacheServer.get(key);
if (!data) {
// Data doesn't exist in cache neither in database
return null;
} else {
data = JSON.parse(data); // Parse cached data
}
return data;
}
When to use: This approach works best when you don't want your application to manage the extra work of cache misses.
Write back
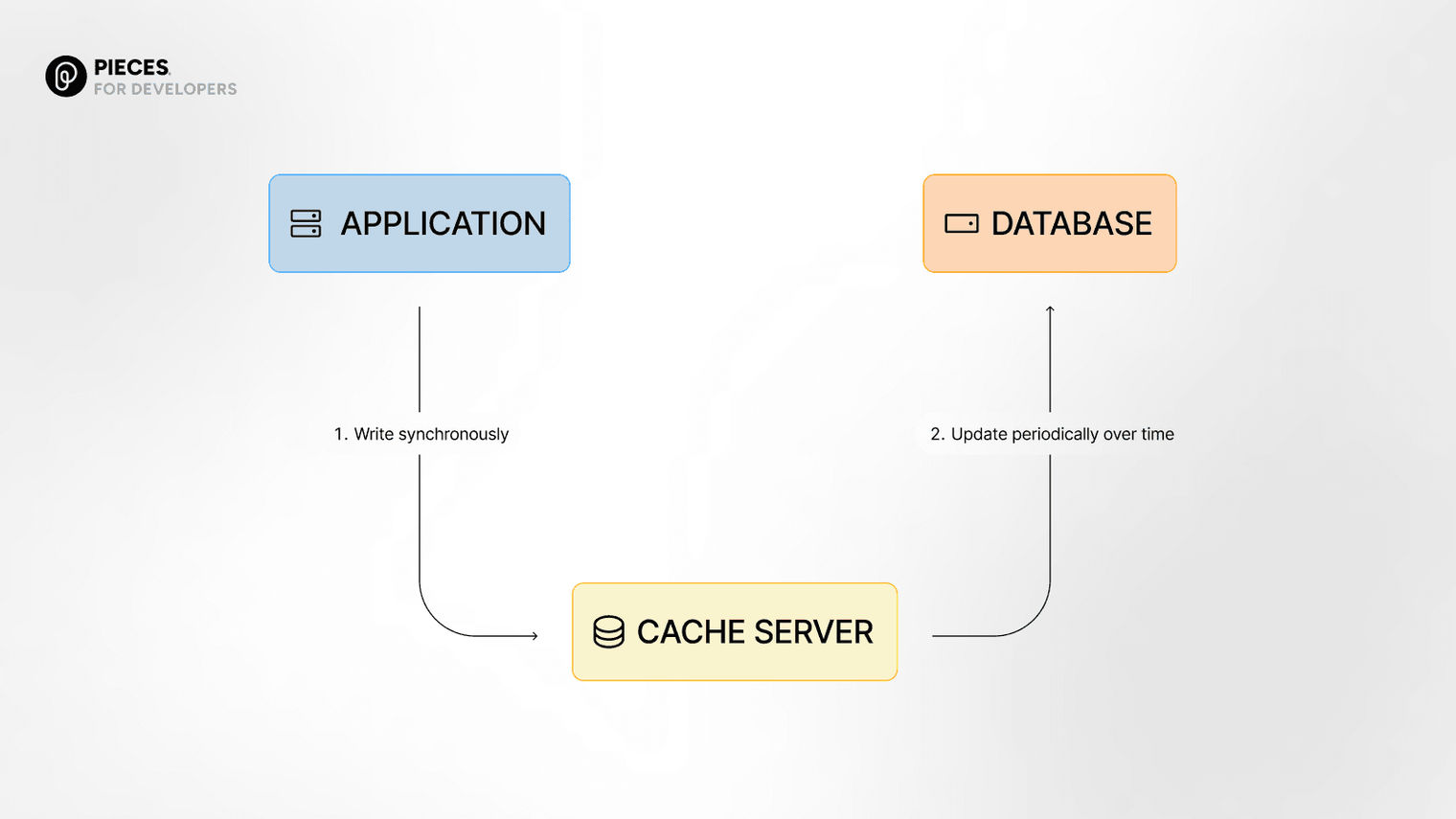
Write-back caching is a bit different. It is a strategy where changes made to data are first written to the cache, and the data in the database is updated later asynchronously.
This enables the application to respond quickly without waiting for the database to update right away.
It's crucial to be careful with it as if the cache crashes before the database gets updated, you might lose some data.
async function writeBackFn(key: string, newData: any): Promise<void> {
await cacheServer.set(key, JSON.stringify(newData)); // Update cache
// The cache server itself will eventually write to the database (pseudo-code)
// setTimeout(() => writeToDatabase(key, newData), 5000)
}
When to use: It’s useful when speed is crucial and don't mind the risk of losing some data.
Write through

Write-through caching is a bit more straightforward approach. Whenever data is written, it’s saved to both the cache and the database at the same time. It starts by first updating the cache and then immediately writes the same data to the database.
This way, you always know that what’s in the cache at every point in time isn't stale and up-to-date with the database.
async function writeThroughFn(key: string, data: any): Promise<void> {
await cacheServer.set(key, JSON.stringify(data)); // Write to the cache
// The cache server update itself first and immediately update the database
// Failure to update both stores render the request a failure
}
When to use: Opt for this method when data consistency is critical, but be aware it might slow down write operations slightly due to the dual writing.
Write around
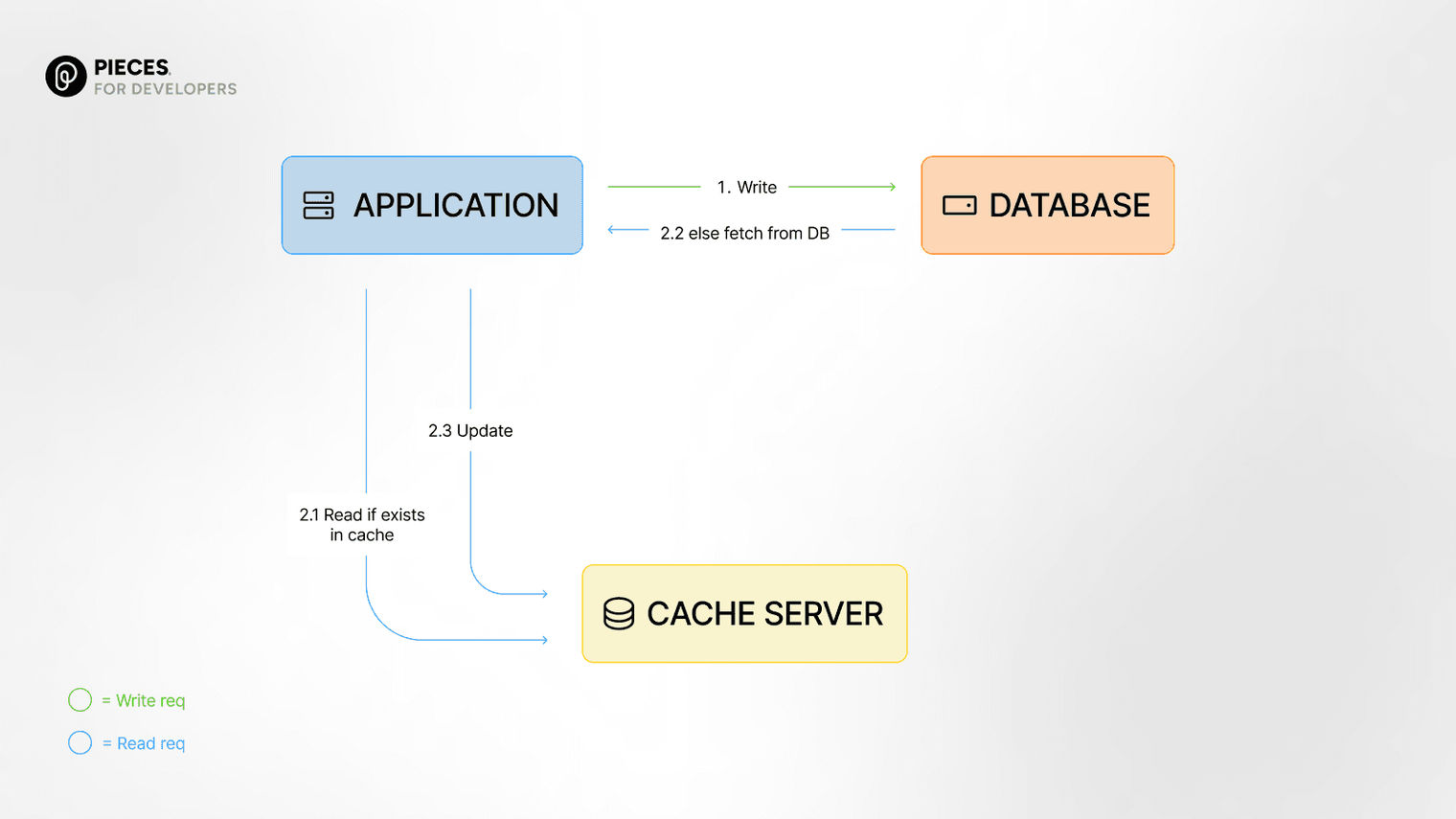
When you use write-around, any new data you want to write is sent straight to the database without touching the cache first. Only when a read request for that data comes in will it be added to the cache.
Think of it like this; if your app receives a write request, it goes directly to the database. This way, you don't have to worry about the cache getting stale right away.
The catch here is that the next time the data is requested, it’ll have to be pulled from the database and not cache, which will be slower. However, once accessed, the cache will have it populated for subsequent requests.
async function writeAroundFn(key: string, data: any): Promise<void> {
await writeToDatabase(key, data); // Write to the database only
// Do not update cache. It will be populated on the next read.
}
When to Use: This strategy is suitable when minimizing cache staleness is a priority.
Cache eviction policies to consider
When it comes to API caching, picking a cache strategy isn't enough. To prevent your cache from running out of memory, it's crucial to pick an eviction policy to dictate how and when data is removed. Here are some common eviction strategies to consider:
Least recently used (LRU)
This works on the principle that data that hasn’t been used in a while is less likely to be accessed again soon. It removes the least recently accessed items when the cache is full, keeping frequently used data available.
Use case: Choose LRU when you expect some data to be consistently used over time
Least frequently used (FIFO)
LFU evicts the least frequently accessed items first. The idea is that if an item has been accessed less often than others, it is less likely to be needed in the future.
Use case: LFU is best when you want to retain high-demand items and are less concerned about the recency of access.
TTL (Time-To-Live)
With TTL policy, each cached item is assigned a specific lifespan. Once the TTL expires, the data is automatically removed from the cache. It's good to note this policy can be combined with other eviction strategies.
Use Case: Use TTL where freshness is critical or data becomes stale over time.
Case studies: Caching at scale
RevenueCat
RevenueCat is a great example of why API caching is essential at scale.
Handling over 1.2 billion API requests per day as of 2023, they openly acknowledge that it wouldn’t be possible without caching. Without it, every request would hit their data stores and backend services directly, leading to massive load, slow response times, and potential outages.
To make caching work efficiently, they implemented some clever techniques.
Since modern in-memory stores are so fast that the bottleneck is often the network round trip, they built a custom cache client that keeps pre-established connections.
This avoids the overhead of setting up new ones, reducing delays caused by TCP handshakes.
They also keep their cache warm at all times using several strategies: dedicated pools for expensive cache data, mirrored pools for read-heavy workloads, guttered pools for caching expired values with low TTL, and key splitting to distribute load across hot keys.
If there’s one simple takeaway, it’s to not hesitate to use and combine different cache pools. They all help to manage your application load during peak usage periods in different ways.
Twitter/X
Twitter’s failure history with caching, as documented by Dan Luu, showcases how it's a double-edged sword at scale when not done right. While caching is essential for performance, unexpected edge cases have led to outages over the years.
One incident involved a cache stampede where a surge of requests overwhelmed the database when a critical cache entry expired. Another failure stemmed from cache inconsistency, resulting in mismatched data across different cache layers.
Twitter has also faced excessive eviction issues, where caches flushed too aggressively, shifting too much load to the backend and triggering downtime.
While fixes were implemented to address these issues, my personal takeaway from an outside-in perspective is that caching issues are often subtle and challenging to diagnose at scale. The only reliable way to resolve them is by having robust monitoring and observability to detect the errors in the first place.
Without it, failures may go unnoticed until they escalate into catastrophic incidents. After all, you can’t fix what you don’t know exists.
Tools for API caching
| Tool | Description | Personal Experience |
|---|---|---|
| Redis | A high-performance, distributed in-memory system for caching various data structures. | This is my de facto choice for several projects and love its support for multiple data structures. If you've ever worked with map coordinates, you'll understand how valuable it is. |
| Memcached | A simple, distributed memory caching system using key-value pairs for small data chunks. | I find myself reaching for memcached whenever I need a simple key/value store as everything it stored as a simple string. |
| Apache Ignite | An open-source, scalable key-value cache store for real-time processing and data analytics. | I’ve only encountered Ignite in enterprise applications. You don’t have to worry about this tool for small to mid size projects. |
| Hazelcast IMDG | A lightweight data grid for in-memory computing supporting numerous data structures. | N/A |
| Apache Geode | An in-memory data grid that offers distributed caching and advanced data processing capabilities. | It’s similar to Ignite (in its focus on data processing), but Geode emphasizes more source events and streams. |
| Mcrouter | A memcached protocol router for scaling memcached deployments. | I reach for Mcrouter whenever my dataset is too large for a single memcached server and needs sharding. |
Avoid these common caching mistakes
When implementing caching, it’s very easy to make common mistakes that could hinder the performance you get out of it. Trust me, I've learned this the hard way.
Here are three mistakes I’ve encountered and how to sidestep them:
Neglecting cache invalidation
One of the biggest mistakes is failing to implement proper cache invalidation—or outright just forgetting about it.
If your cache isn’t updated when the underlying data changes, you'll end up accessing stale data. Techniques like time-based expiration or event-driven updates work well to avoid this.
Over-caching
It might seem tempting to cache everything in sight—after all, why not? But then I quickly learned the hard way that over-caching can lead to thrashing.
When you store too much data, it can inflate memory usage, ultimately slowing down retrieval times.
Instead, focus on caching only the most frequently accessed and expensive to generate data.
On the plus side, a leaner cache can help keep costs down—who doesn’t want a cheaper bill at the end of the month?
Mishandling hot keys
Hot keys are the pieces of data that receive a high volume of requests. If these keys aren’t refreshed properly, it can lead to a thundering herd problem, where too many requests hit your servers simultaneously due to a cache miss, slowing everything down.
To prevent this, it’s important to have a concurrency strategy in place, like optimistic locking.
This allows one process to refresh the data while other requests either use the stale data or wait.
Final thoughts
There’s no doubt that caching is a powerful concept that can boost the performance of your application. While it isn’t a one-size-fits-all solution, it remains an essential element when building APIs.
The right choice among various API caching strategies will ultimately depend on your application's requirements and infrastructure.
Though I couldn't cover every possible corner case that can arise with caching, here are some articles I would recommend you check to complement this topic: